Reference-driven image completion, which restores missing regions in a target view using additional images, is particularly challenging when the target view differs significantly from the references.
Existing generative methods rely solely on diffusion priors and, without geometric cues such as camera pose or depth, often produce misaligned or implausible content.
We propose GeoComplete, a novel framework that incorporates explicit 3D structural guidance to enforce geometric consistency in the completed regions, setting it apart from prior image-only approaches.
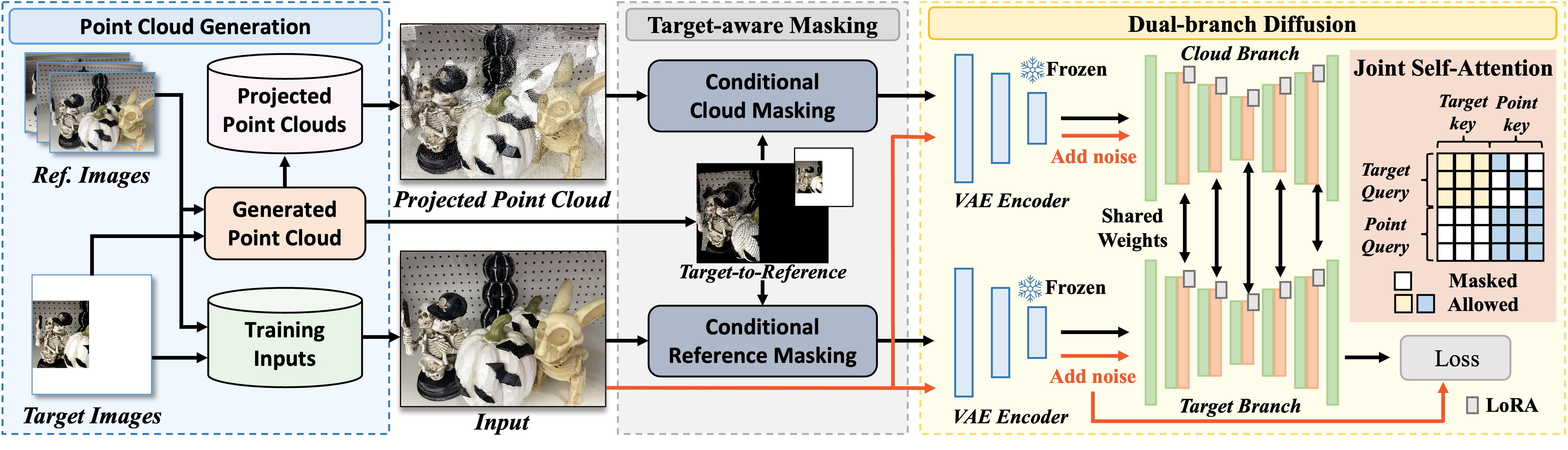
GeoComplete introduces two key ideas: conditioning the diffusion process on projected point clouds to infuse geometric information, and applying target-aware masking to guide the model toward relevant reference cues.
The framework features a dual-branch diffusion architecture. One branch synthesizes the missing regions from the masked target, while the other extracts geometric features from the projected point cloud.
Joint self-attention across branches ensures coherent and accurate completion.
To address regions visible in references but absent in the target, we project the target view into each reference to detect occluded areas, which are then masked during training.
This target-aware masking directs the model to focus on useful cues, enhancing performance in difficult scenarios.
To our knowledge, GeoComplete is the first to tightly couple explicit 3D geometry with diffusion-based image completion in a unified framework.
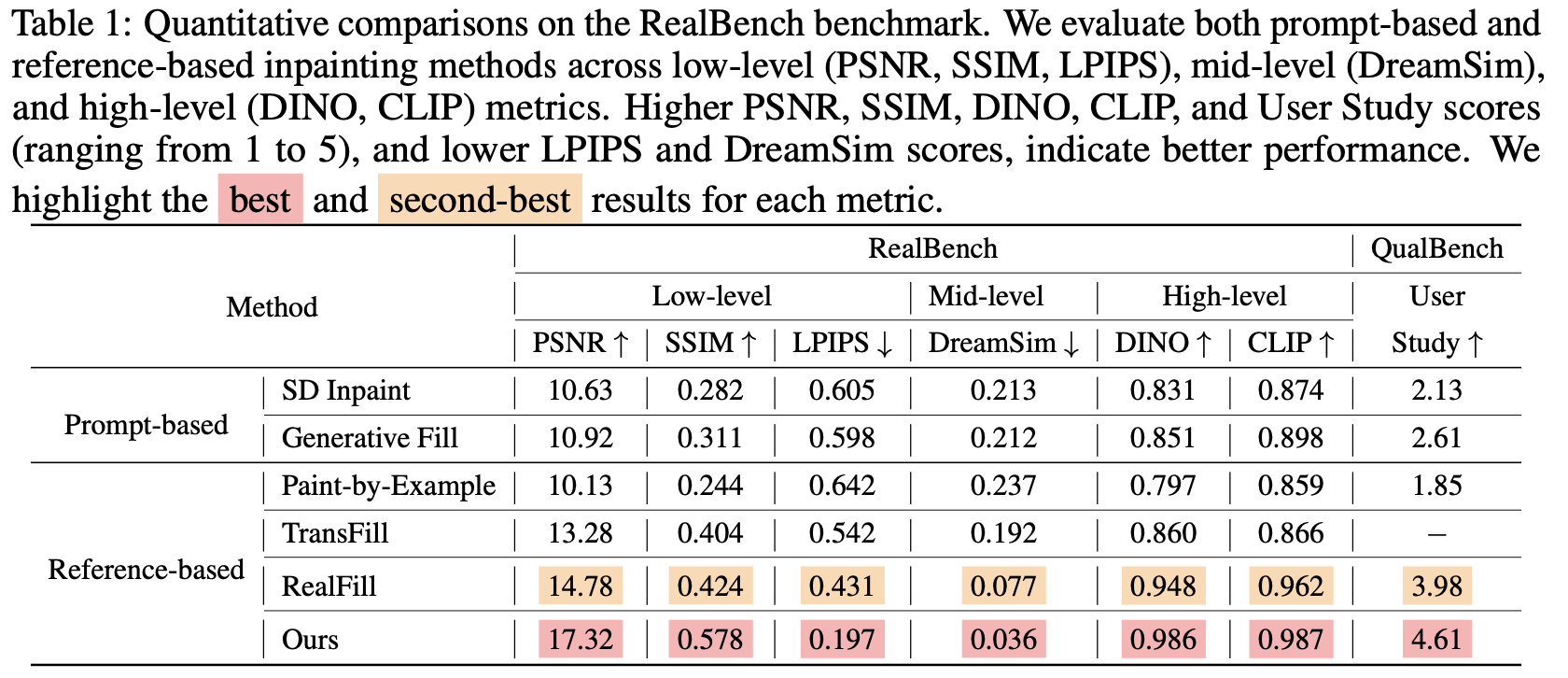
Experiments show that GeoComplete achieves a 17.1% PSNR improvement over state-of-the-art methods, significantly boosting geometric accuracy while maintaining high visual quality.